Benjamin Gompertz and the Gompertz distribution
Central to baytaAAR is the Gompertz distribution, named
after the British mathematician B. Gompertz
(1779–1865) who first presented it in 1825 (Gompertz 1825).
Hazard, survival and the ensuing probability distribution are defined as follows (see also Wood et al. 2002, 146):
Despite or even because of its simplicity, it is still widely
applied. Instrumental for baytaAAR is the strong empirical
correlation between its two parameters
and
,
the so-called Strehler-Mildvan-correlation (Strehler and Mildvan 1960). This makes it
possible to reformulate it as essentially a one-parameter distribution
that still captures human mortality adequately. The empirical
correlation between the two parameters at the age of 15 years was
defined by T. Sasaki and O. Kondo (2016, 529
fig. 1) as follows:
Here, a normal distribution with a variance term of 0.0823 serves as a basis to model log-transformed . If the variance term is omitted, the relationship between and becomes deterministic:
If the starting age is not 15, we
simulate the relation with the internal function
gomp.a0().
The parameter is estimated from the observed data, thereby defining the overall level of mortality of the respective population and the age range of the individuals. The following figure, taken from Müller-Scheeßel et al. (2024, 4 fig. 1), shows Gompertz hazard, survival and density curves with different values:
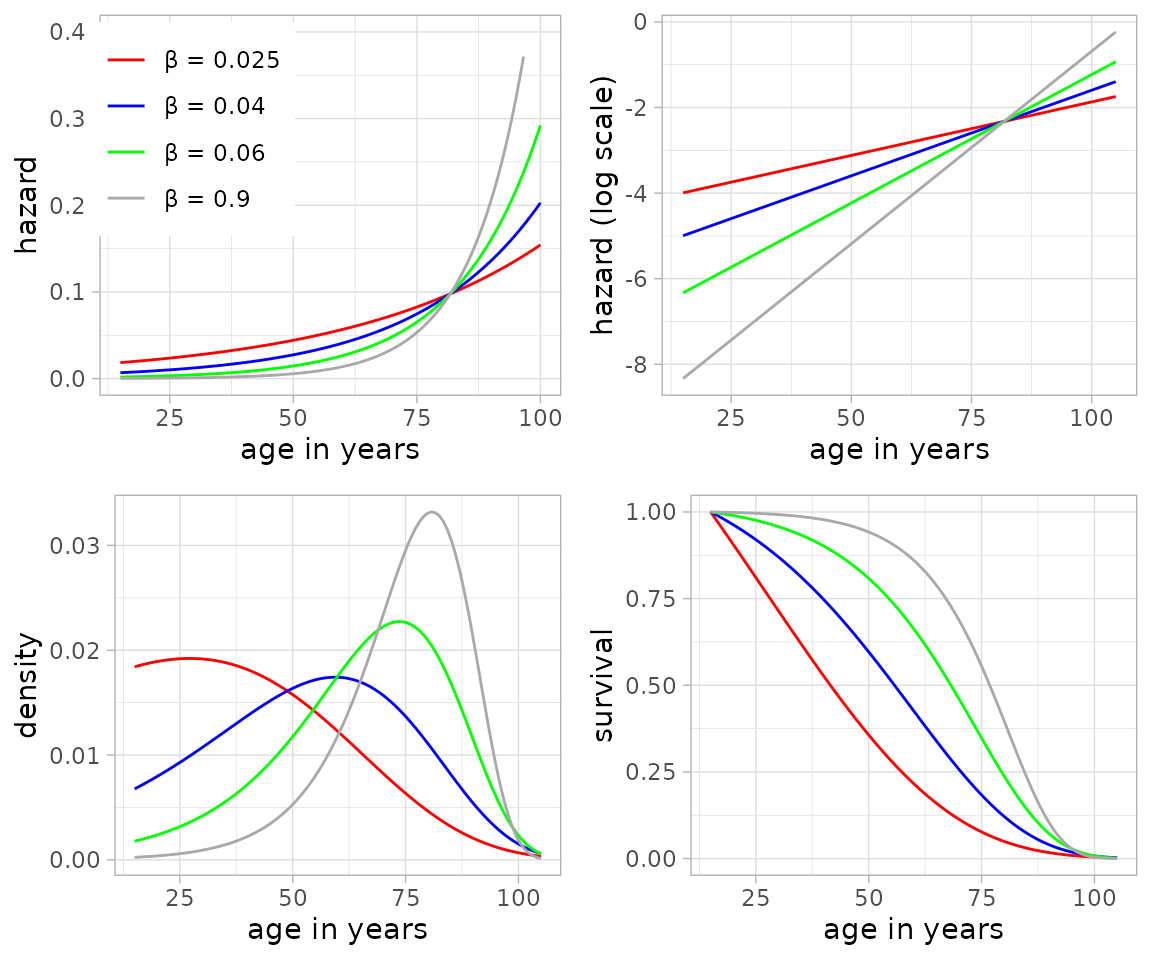
The modal age M derives naturally from the Gompertz model. It equals the peak of the curves in the lower left image. It is a useful parameter for adult mortality as it does not change with the starting observed age as life expectancy does (Missov et al. 2015). So, for example, e20 (life expectancy from age 20) will differ from e25 (life expectancy from age 25), and the one is not easily translated to the other. This is not the case with the modal age M. The modal age M is defined as:
The Gompertz distribution with NIMBLE and JAGS
The Gompertz distribution is implemented in NIMBLE and JAGS with the
so-called ‘ones trick’, which is a simple, convenient way to implement
custom distributions (Kruschke 2015,
214–15). Theoretically, NIMBLE allows custom functions to be
added as nimble functions compiled at runtime but we wanted
to make sure that the results of the two frameworks are as similar as
possible.
Mathematical notation
Building on this mortality model, we now describe how it is embedded
in the latent trait framework used by baytaAAR.
The observed data are written as where indexes individuals from 1 to and indexes traits (skeletal age “indicators”) from 1 to . Because the data are recorded for ordinal categorical traits the values for each trait are positive integers. The number of states per trait is given as . With states per trait , there are thresholds for each trait.
As stated above, the Gompertz model has two parameters and . The prior for is:
where
denotes a uniform distribution with density 1/(b - a)
between a and b. Simplifying the equation of
Sasaki and Kondo above,
is given deterministically as:
The prior for individual ages , where is the age-at-death, is
The starting age
is usually at 15 years, and the distribution is truncated at
100 years - starting age, reflecting a maximally expected
life span of 100 years.
The thresholds within each trait are represented using the symbol , so that for a trait with five stages, the thresholds are . To ensure identifiability, all .
The priors for thresholds with more than two states are:
where
is a truncated normal distribution with left truncation at
a and right truncation at b. Because the
thresholds must be ordered, for the JAGS-model,
,
and the simulated thresholds are sorted in ascending order. NIMBLE does
not have a sort-function, so there
.
For each individual there is a vector of latent traits of length (number of traits). For the simple probit model with conditional independence, the elements of these vectors are modeled separately with normal distributions:
For identifiability, is fixed at (1).
For the complex probit model, these vectors follow a multivariate normal distribution:
We use a “flat” prior by Lewandowski, Kurowicka, & Joe (2009) for the correlation matrix:
For , this prior is uniform over the space of correlation matrices.
The components of the vector are:
with the priors for the and parameters within each trait being:
JAGS and NIMBLE both have the distribution dinterval
which is difficult to express succinctly:
Because dinterval indexes categories from
zero instead of one, the observed trait levels
and thresholds are internally shifted by one unit.
The proper initialization of the chains is crucial in probit
regression. Each chain starts with different parameter values to enhance
mixing, and most parameters are initialized with random values from
uniform distributions. For Gompertz
initial values are drawn from 0.02–0.1, for
the range is 0.5–1, and for
–10––3. The init value for age
is 20–40. To this value, the starting value
(15 by default) is added. The correlation matrix is for all
chains initialized with an identity matrix (ones on the diagonal and
zeros elsewhere). The thresholds are initialized with
k + 0.5 and the vector of latent traits
with
.